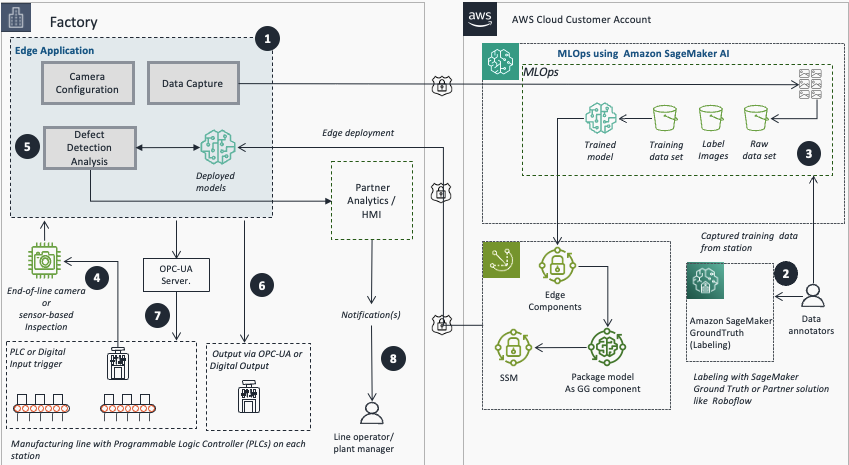
Transição do Amazon Lookout for Vision para SageMaker
Em outubro de 2024, a AWS anunciou a descontinuação do Amazon Lookout for Vision, com previsão de encerramento em 31 de outubro de 2025. Como parte de sua estratégia de transição, a empresa recomenda que clientes interessados em soluções de inteligência artificial e aprendizado de máquina para visão computacional utilizem as ferramentas do Amazon SageMaker AI.
A boa notícia é que a AWS disponibilizou no AWS Marketplace os modelos subjacentes que alimentavam o serviço descontinuado. Esses modelos podem ser ajustados usando o Amazon SageMaker para casos de uso específicos, oferecendo flexibilidade total de integração com infraestruturas existentes de hardware e software. Quando executados na nuvem, os custos envolvem apenas a infraestrutura necessária para treinamento ou inferência.
Vantagens da Migração para SageMaker
A transição proporciona ganhos significativos em flexibilidade e controle. Com o SageMaker, é possível treinar modelos em instâncias maiores para reduzir o tempo de processamento. Além disso, usuários podem ajustar hiperparâmetros que antes não eram disponíveis no console do Lookout for Vision. Por exemplo, é possível desabilitar a cabeça do classificador binário em modelos de segmentação semântica, tornando a solução mais tolerante a variações de iluminação e fundo.
Outro destaque é o controle sobre o tempo máximo de treinamento, que no Lookout for Vision era limitado a 24 horas. Agora, organizações podem customizar esse parâmetro conforme suas necessidades.
Recursos e Modelos Disponíveis
A AWS coloca à disposição dois tipos principais de modelos:
- Classificação binária: para categorizar imagens como normais ou anômalas
- Segmentação semântica: para identificar regiões específicas com defeitos em uma imagem
Ambos podem ser treinados nas contas próprias da AWS para implantação na nuvem ou em dispositivos edge. O repositório GitHub do Amazon Lookout for Vision foi atualizado com um Jupyter Notebook que facilita o treinamento de datasets com esses dois tipos de modelos e seu empacotamento.
Para rotular dados além do conjunto amostral, é possível usar o Amazon SageMaker Ground Truth para crowdsourcing ou permitir que equipes privadas façam a anotação. Alternativas incluem soluções de parceiros como Edge Impulse, Roboflow e SuperbAI.
Pré-Requisitos
Antes de começar, certifique-se de ter em lugar:
- Amazon SageMaker Studio ou Amazon SageMaker Unified Studio para desenvolvimento integrado
- Função Controle de Identidade e Acesso (IAM) com permissões apropriadas, incluindo acesso ao Amazon S3, operações no SageMaker e subscrição ao AWS Marketplace
- Subscrição a um modelo de detecção de defeitos por visão computacional no AWS Marketplace
- Dados etiquetados (é possível usar amostras como o cookie-dataset ou aliens-dataset do GitHub)
- Conhecimento básico de criar instâncias Jupyter no SageMaker e executar notebooks
Configuração do Processo de Etiquetagem
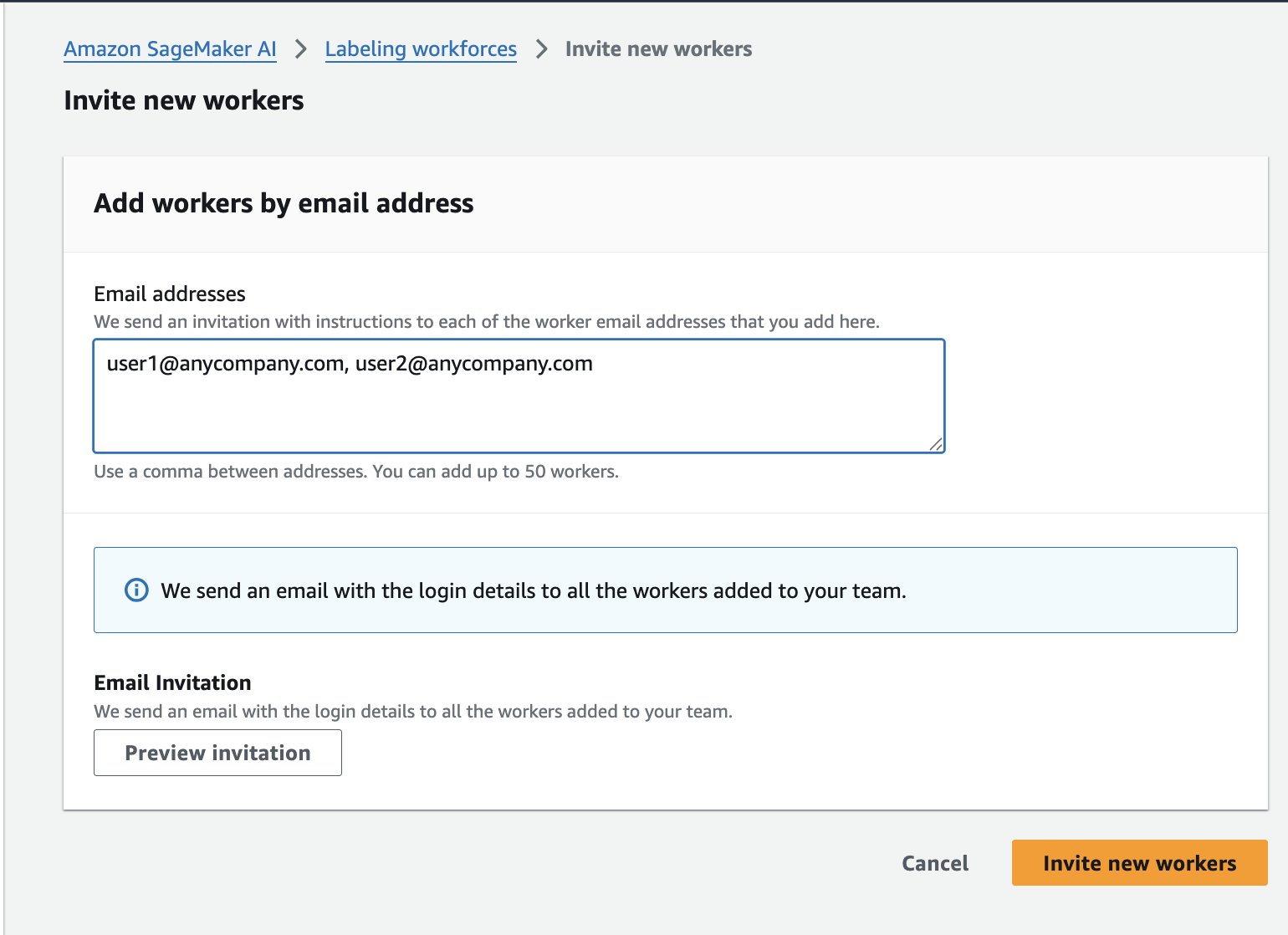
O primeiro passo da jornada envolve preparar os dados para treinamento. A AWS oferece o Ground Truth, que possibilita criar equipes privadas de anotadores e organizar o trabalho de rotulação.
No console do SageMaker AI, navegue até Ground Truth e selecione a opção de criar uma equipe privada. Após definir nome e configurações iniciais, você pode convidar membros da sua equipe por e-mail, enviando automaticamente convites com credenciais de acesso.
Preparação e Etiquetagem de Datasets
Uma vez que a equipe está pronta, o próximo passo é preparar o dataset. Faça upload das imagens para um bucket Amazon S3 e organize-as em uma estrutura única de diretório, combinando imagens normais e anômalas.
Para automatizar esse processo, você pode usar um script no AWS CloudShell:
#!/bin/bash
# Clone o repositório
git clone https://github.com/aws-samples/amazon-lookout-for-vision.git
cd amazon-lookout-for-vision/aliens-dataset
# Remove diretório anterior se existir
rm -rf all
# Cria novo diretório
mkdir -p all
# Copia imagens normais
cp normal/*.png all/
# Copia imagens anômalas com sufixo
cd "$(dirname "$0")/amazon-lookout-for-vision/aliens-dataset"
for file in anomaly/*.png; do
if [ -f "$file" ]; then
filename=$(basename "$file")
cp "$file" "all/${filename}.anomaly.png"
fi
done
# Verifica contagem
echo "Imagens normais: $(find normal -name "*.png" | wc -l)"
echo "Imagens anômalas: $(find anomaly -name "*.png" | wc -l)"
echo "Total no diretório all: $(find all -type f | wc -l)"
# Upload para S3
aws s3 cp all/ s3:///aliens-dataset-all/ --recursive
# Limpeza
cd ../..
rm -rf amazon-lookout-for-vision Alternativamente, com a CLI da AWS configurada, você pode usar comandos manuais. Depois de fazer upload, acesse o console do SageMaker, navigate para Ground Truth e crie um novo job de etiquetagem. Configure a localização dos dados no S3, escolha "Configuração Automática de Dados" e selecione "Imagem" como tipo de dados.
Para o tipo de tarefa, escolha "Classificação de Imagem (Rótulo Único)" para classificação binária ou "Segmentação Semântica" conforme sua necessidade. Crie dois rótulos: "normal" e "anomalia". Uma vez que o job é iniciado, trabalhadores acesso o portal de etiquetagem e rotulam cada imagem conforme as instruções fornecidas.
Treinamento do Modelo
Após concluir a etiquetagem, use os dados rotulados para treinar o modelo de detecção de defeitos. Primeiro, subscrevam-se ao modelo no AWS Marketplace. Copie o ARN (Identificador de Recurso da Amazon) do modelo para referência posterior.
Em seguida, crie uma instância Jupyter do SageMaker. Para essa tarefa, uma instância do tipo m5.2xl é adequada, com volume de 128 GB (o padrão de 5 GB é insuficiente). GPU não é obrigatória na instância do notebook, pois o SageMaker ativa automaticamente instâncias habilitadas com GPU durante o treinamento.
Clone o repositório GitHub dentro da instância Jupyter e localize a pasta relevante. No notebook, defina o ARN do modelo que você subscreveu:
# TODO: altere para usar o algoritmo SageMaker subscrito
algorithm_name = ""
# Inicializa a sessão SageMaker e obtém a função de execução
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = get_execution_role()
# Nome do projeto para identificar no S3
project = "ComputerVisionDefectDetection"
Fonte
Train custom computer vision defect detection model using Amazon SageMaker (https://aws.amazon.com/blogs/machine-learning/train-custom-computer-vision-defect-detection-model-using-amazon-sagemaker/)