O que é o Amazon Bedrock Custom Model Import?
O Amazon Bedrock Custom Model Import agora amplia seus recursos para incluir modelos OpenAI com pesos abertos, particularmente as variantes GPT-OSS de 20 bilhões e 120 bilhões de parâmetros. Esse serviço permite que as organizações importem modelos customizados diretamente em um ambiente serverless, onde é possível acessar simultaneamente modelos de fundação (FMs) por meio de uma interface unificada.
A principal vantagem dessa abordagem é eliminar a necessidade de gerenciar múltiplos endpoints ou infraestruturas isoladas. Após fazer o upload dos arquivos do modelo para o Amazon S3 (Amazon Simple Storage Service), a AWS assume todas as operações complexas: provisionamento de GPUs (Processadores Gráficos), configuração de servidores de inferência e dimensionamento automático conforme a demanda. Dessa forma, as equipes podem concentrar-se no desenvolvimento de aplicações enquanto a infraestrutura é gerenciada automaticamente.
Compatibilidade com a API do OpenAI
Os modelos GPT-OSS suportam completamente a API de Conclusões de Chat do OpenAI, mantendo compatibilidade integral com aplicações existentes. Isso significa que recursos como matrizes de mensagens, definições de papéis (sistema, usuário ou assistente) e estruturas de resposta padrão — incluindo métricas de uso de tokens — funcionam sem modificações.
Ao apontar suas aplicações para os endpoints do Amazon Bedrock, o código existente requer mudanças mínimas ou nenhuma mudança. Essa continuidade reduz significativamente o esforço de migração e o risco de regressões em produção.
Entendendo os Modelos GPT-OSS
Os modelos GPT-OSS representam os primeiros modelos de linguagem com pesos abertos lançados pela OpenAI desde o GPT-2, distribuídos sob a licença Apache 2.0. Isso significa que qualquer organização pode fazer download, modificar e utilizar esses modelos sem custos adicionais, inclusive para aplicações comerciais.
GPT-OSS-20B (20 Bilhões de Parâmetros)
Este modelo é otimizado para situações onde velocidade e eficiência são críticas. Apesar de possuir 21 bilhões de parâmetros, apenas 3,6 bilhões são ativados por token, permitindo execução em dispositivos com apenas 16 GB de memória. Com 24 camadas, 32 especialistas (4 ativos por token) e janela de contexto de 128k, oferece desempenho comparável ao o3-mini da OpenAI com a vantagem de poder ser implantado localmente para respostas mais rápidas.
GPT-OSS-120B (120 Bilhões de Parâmetros)
Desenvolvido para tarefas complexas de raciocínio — como codificação, matemática e uso de ferramentas em agentes automáticos — este modelo ativa 5,1 bilhões de parâmetros por token. Com 36 camadas, 128 especialistas (4 ativos por token) e janela de contexto de 128k, atinge desempenho equivalente ao o4-mini da OpenAI executando eficientemente em uma única Unidade de Processamento Gráfico (GPU) de 80 GB.
Arquitetura de Mistura de Especialistas
Ambos os modelos utilizam uma arquitetura de Mistura de Especialistas (MoE). Nessa abordagem, diferentes subconjuntos dos componentes do modelo (chamados de especialistas) tratam diferentes tipos de tarefas. Para cada requisição, apenas os especialistas mais relevantes são ativados, oferecendo desempenho potente enquanto mantém os custos computacionais gerenciáveis.
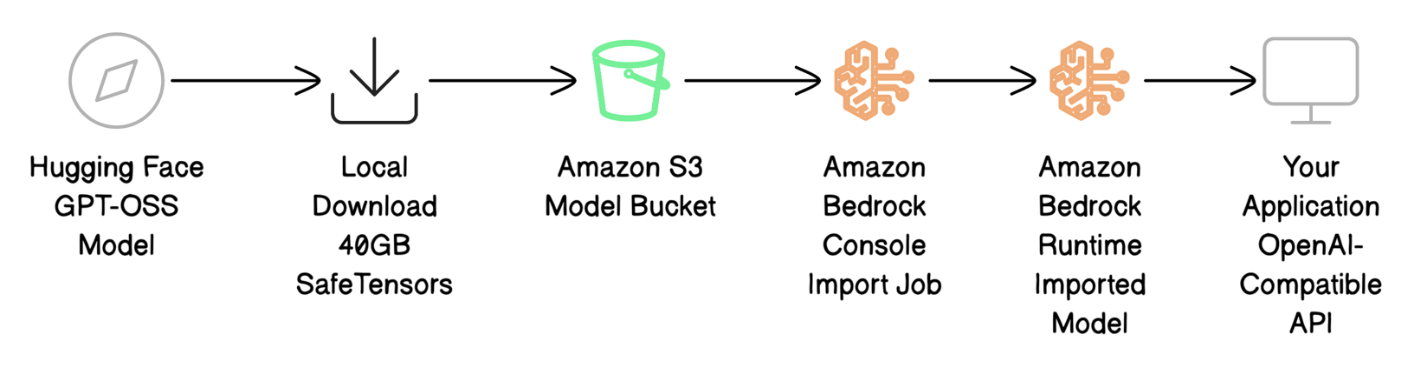
Formato dos Arquivos do Modelo GPT-OSS
Quando você faz download de modelos GPT-OSS do Hugging Face, recebe vários tipos de arquivo que trabalham em conjunto:
- Arquivos de pesos (.safetensors): Contêm os parâmetros reais do modelo
- Arquivos de configuração (config.json): Definem como o modelo funciona
- Arquivos do tokenizador: Realizam o processamento de texto
- Arquivo de índice (model.safetensors.index.json): Mapeia dados de pesos para arquivos específicos
O arquivo de índice exige uma estrutura específica para funcionar com o Amazon Bedrock. Deve incluir um campo de metadados no nível raiz, que pode estar vazio ({}) ou conter o tamanho total do modelo (que precisa estar abaixo de 200 GB para modelos de texto).
Modelos do Hugging Face às vezes incluem campos de metadados extras — como total_parameters — que o Amazon Bedrock não suporta. Esses campos devem ser removidos antes da importação. A estrutura correta deve ser assim:
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
}Certifique-se de excluir o diretório .metal antes de iniciar o upload para o S3.
Processo de Implantação
O fluxo de implantação envolve quatro etapas principais:
- Fazer download dos arquivos do modelo do Hugging Face e prepará-los para AWS
- Enviar os arquivos do modelo para o Amazon S3
- Usar o Amazon Bedrock Custom Model Import para trazer o modelo para o Bedrock
- Invocar o modelo com chamadas à API compatível com OpenAI para testar a implantação
Pré-requisitos
Antes de começar a implantar seu modelo GPT-OSS, certifique-se de ter:
- Uma conta AWS ativa com permissões apropriadas
- Permissões do AWS Identity and Access Management (IAM) para:
- Criar trabalhos de importação de modelos no Amazon Bedrock
- Fazer upload de arquivos para o Amazon S3
- Invocar modelos após implantação
- Usar a função de serviço do Custom Model Import
- Um bucket S3 na sua região AWS de destino
- Aproximadamente 40 GB de espaço em disco local para download do modelo
- Acesso à Região US East 1 (N. Virginia) — obrigatória para modelos personalizados baseados em GPT-OSS
- Interface de Linha de Comando da AWS (AWS CLI) versão 2.x instalada
- Interface de Linha de Comando do Hugging Face (instale com
pip install -U "huggingface_hub[cli]")
Download e Preparação dos Arquivos do Modelo
Para fazer download do modelo GPT-OSS usando a biblioteca Hugging Face Hub com transferência rápida habilitada:
import os
os.environ['HF_HUB_ENABLE_HF_TRANSFER'] = '1'
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="Tonic/med-gpt-oss-20b",
local_dir="./med-gpt-oss-20b",
)
print(f"Download complete! Model saved to: {local_dir}")Após o download ser concluído (típicamente entre 10 a 20 minutos para 40 GB), verifique a estrutura do arquivo model.safetensors.index.json. Edite-o se necessário para garantir que o campo de metadados exista (pode estar vazio):
{
"metadata": {},
"weight_map": {
"lm_head.weight": "model-00009-of-00009.safetensors",
...
}
}Envio dos Arquivos do Modelo para o Amazon S3
Antes de importar seu modelo, você deve armazenar os arquivos em um bucket S3 onde o Amazon Bedrock possa acessá-los.
Usando a Interface de Linha de Comando da AWS (AWS CLI), você pode sincronizar os arquivos diretamente:
aws s3 sync ./med-gpt-oss-20b/ s3://amzn-s3-demo-bucket/med-gpt-oss-20b/O envio de 40 GB normalmente é concluído em 5 a 10 minutos. Para verificar se os arquivos foram enviados:
aws s3 ls s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --human-readableAnote o URI do S3 (por exemplo, s3://amzn-s3-demo-bucket/med-gpt-oss-20b/) para usar no trabalho de importação. Os arquivos de saída são criptografados com as configurações de criptografia do bucket S3, seja com criptografia do lado do servidor SSE-S3 (Criptografia de Lado do Servidor S3) ou AWS Key Management Service (AWS KMS) dependendo de como você configurou o bucket.
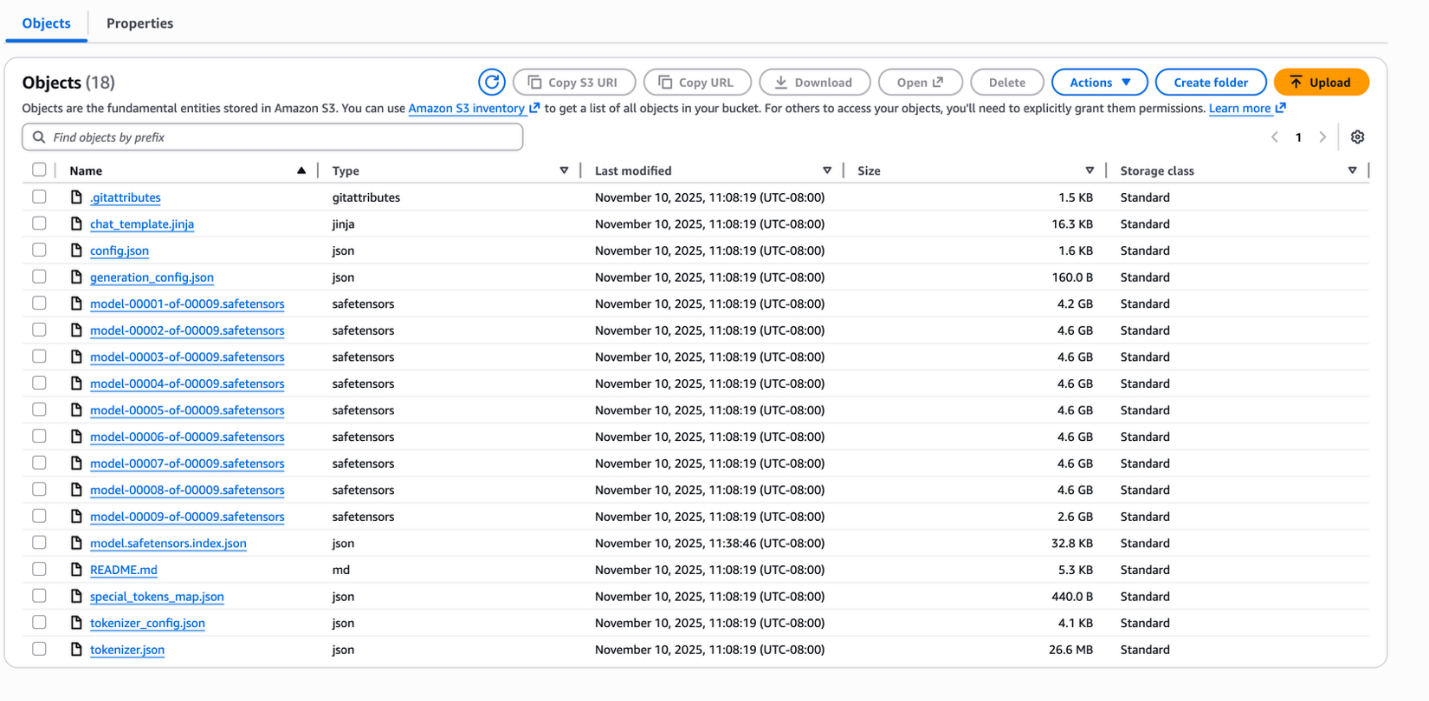
Importação do Modelo no Amazon Bedrock
Após fazer upload dos arquivos do modelo para o S3, você pode importá-lo para o Amazon Bedrock, onde será processado e disponibilizado para inferência.
Use o AWS CLI para criar o trabalho de importação:
aws bedrock create-model-import-job \
--job-name "gpt-oss-20b-import-$(date +%Y%m%d-%H%M%S)" \
--imported-model-name "gpt-oss-20b" \
--role-arn "arn:aws:iam::YOUR-ACCOUNT-ID:role/YOUR-ROLE-NAME" \
--model-data-source "s3DataSource={s3Uri=s3://amzn-s3-demo-bucket/med-gpt-oss-20b/}"A importação do modelo normalmente é concluída em 10 a 15 minutos para um modelo de 20B de parâmetros. Você pode acompanhar o progresso no console do Amazon Bedrock ou via AWS CLI. Após a conclusão, anote seu importedModelArn, que será usado para invocar o modelo.
Invocação do Modelo com API Compatível com OpenAI
Após a conclusão da importação, você pode testar o modelo usando o formato familiar da API de Conclusões de Chat do OpenAI para verificar se está funcionando corretamente.
Crie um arquivo chamado test-request.json com o seguinte conteúdo:
{
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant."
},
{
"role": "user",
"content": "What are the common symptoms of Type 2 Diabetes?"
}
],
"max_tokens": 500,
"temperature": 0.7
}Use o AWS CLI para enviar a requisição ao seu endpoint de modelo importado:
aws bedrock-runtime invoke-model \
--model-id "arn:aws:bedrock:us-east-1:YOUR-ACCOUNT-ID:imported-model/MODEL-ID" \
--body file://test-request.json \
--cli-binary-format raw-in-base64-out \
response.json
cat response.json | jq '.'A resposta retorna no formato padrão do OpenAI:
{
"id": "chatcmpl-f06adcc78daa49ce9dd2c58f616bad0c",
"object": "chat.completion",
"created": 1762807959,
"model": "YOUR-ACCOUNT-ID-MODEL-ID",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Type 2 Diabetes often presents with a range of symptoms...",
"refusal": null,
"function_call": null,
"tool_calls": []
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 98,
"completion_tokens": 499,
"total_tokens": 597
}
}A estrutura da resposta corresponde exatamente ao formato do OpenAI — choices contém a resposta, usage fornece contagens de tokens e finish_reason indica o status de conclusão. O código existente de análise de resposta do OpenAI funciona sem modificações.
Migração do OpenAI para Amazon Bedrock
Migrar do OpenAI requer apenas mudanças mínimas no código — apenas o método de invocação muda, enquanto as estruturas de mensagens permanecem idênticas.
No OpenAI:
import openai
response = openai.ChatCompletion.create(model="....", messages=[...])No Amazon Bedrock:
import boto3, json
bedrock = boto3.client('bedrock-runtime')
response = bedrock.invoke_model(
modelId='arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID',
body=json.dumps({"messages": [...]})
)A migração é direta e oferece vantagens significativas: custos previsíveis, melhor privacidade de dados e a capacidade de ajustar modelos para necessidades específicas.
Limpeza de Recursos
Quando terminar, limpe seus recursos para evitar cobranças desnecessárias:
aws bedrock delete-imported-model --model-identifier "arn:aws:bedrock:us-east-1:ACCOUNT:imported-model/MODEL-ID"
aws s3 rm s3://amzn-s3-demo-bucket/med-gpt-oss-20b/ --recursiveSe não precisar mais da função IAM, delete-a usando o console do IAM.
Práticas Recomendadas
Considere as seguintes práticas recomendadas ao trabalhar com importação de modelos:
- Validação de arquivos: Antes de fazer upload, verifique se
model.safetensors.index.jsontem a estrutura de metadados correta, se os arquivos safetensors referenciados existem e se os tokenizadores são suportados. A validação local economiza tempo em tentativas de importação. - Segurança: No console do Amazon Bedrock, crie funções IAM automaticamente com permissões de privilégio mínimo. Para múltiplos modelos, use prefixos S3 separados para manter isolamento.
- Versionamento: Use caminhos descritivos no S3 (como
gpt-oss-20b-v1.0/) ou nomes de trabalhos de importação com data para rastreamento de implantações.
Custos e Disponibilidade
Você é cobrado pela execução de inferência com modelos customizados que importa no Amazon Bedrock. Para mais detalhes, consulte Calcular o custo de executar um modelo customizado e Preços do Amazon Bedrock.
O Amazon Bedrock Custom Model Import está disponível em múltiplas regiões, com suporte se expandindo para regiões adicionais em breve. Consulte Suporte de recursos por região AWS no Amazon Bedrock para as atualizações mais recentes. Os modelos GPT-OSS estarão inicialmente disponíveis na Região US-East-1 (N. Virginia).
Conclusão
O Amazon Bedrock Custom Model Import oferece às organizações a capacidade de trazer modelos GPT-OSS para um ambiente gerenciado e serverless, mantendo compatibilidade total com a API do OpenAI. Isso reduz significativamente o esforço de migração de aplicações existentes para a AWS.
Os benefícios práticos são evidentes: segurança de nível empresarial, dimensionamento automático, controle de custos previsível, privacidade de dados aprimorada e a possibilidade de ajustar modelos com seus próprios dados proprietários. Tudo isso com mudanças mínimas no código existente.
Tem dúvidas ou feedback? Conecte-se com a comunidade através do AWS re:Post para Amazon Bedrock — eles adorariam ouvir sobre sua experiência.
Fonte
Deploy GPT-OSS models with Amazon Bedrock Custom Model Import (https://aws.amazon.com/blogs/machine-learning/deploy-gpt-oss-models-with-amazon-bedrock-custom-model-import/)