A Demanda por Inferência mais Rápida
Os modelos de IA generativa continuam crescendo em escala e capacidade, intensificando a necessidade de inferência mais veloz e eficiente. Aplicações que funcionam com estes modelos precisam de baixa latência e desempenho consistente sem comprometer a qualidade dos resultados gerados. A AWS anunciou novos aprimoramentos em seu kit de ferramentas de otimização de inferência no SageMaker AI, expandindo o suporte para a decodificação especulativa baseada em EAGLE para mais arquiteturas de modelos.
Essas atualizações facilitam a aceleração do processo de decodificação, permitem otimizar o desempenho utilizando dados específicos da sua aplicação e possibilitam o deploy de modelos com maior throughput por meio do fluxo de trabalho familiar do SageMaker AI.
Entendendo o EAGLE
EAGLE é uma sigla para Algoritmo de Extrapolação para Maior Eficiência em Modelos de Linguagem (Extrapolation Algorithm for Greater Language-model Efficiency). A técnica funciona acelerando a decodificação de modelos de linguagem grandes ao prever tokens futuros diretamente a partir das camadas ocultas do modelo.
Uma das características principais é a capacidade de otimização dinâmica baseada em seus dados. Quando você orienta a otimização usando dados reais da sua aplicação, as melhorias se alinham com os padrões e domínios específicos que você atende, produzindo uma inferência mais rápida que reflete suas cargas de trabalho reais e não apenas benchmarks genéricos.
Dependendo da arquitetura do modelo, o SageMaker AI treina cabeçalhos EAGLE 3 ou EAGLE 2. É importante notar que esse treinamento e otimização não se limita a uma única operação. Você pode começar utilizando os conjuntos de dados fornecidos pelo SageMaker para treinamento inicial, mas conforme coleta e reúne seus próprios dados, pode também fazer ajuste fino usando seu próprio conjunto de dados curado para desempenho altamente adaptativo e específico à sua carga de trabalho.
Um exemplo prático seria usar uma ferramenta como Captura de Dados para curar seu próprio conjunto de dados ao longo do tempo a partir de requisições em tempo real que atingem seu modelo hospedado. Trata-se de um recurso iterativo com múltiplos ciclos de treinamento para melhorar continuamente o desempenho.
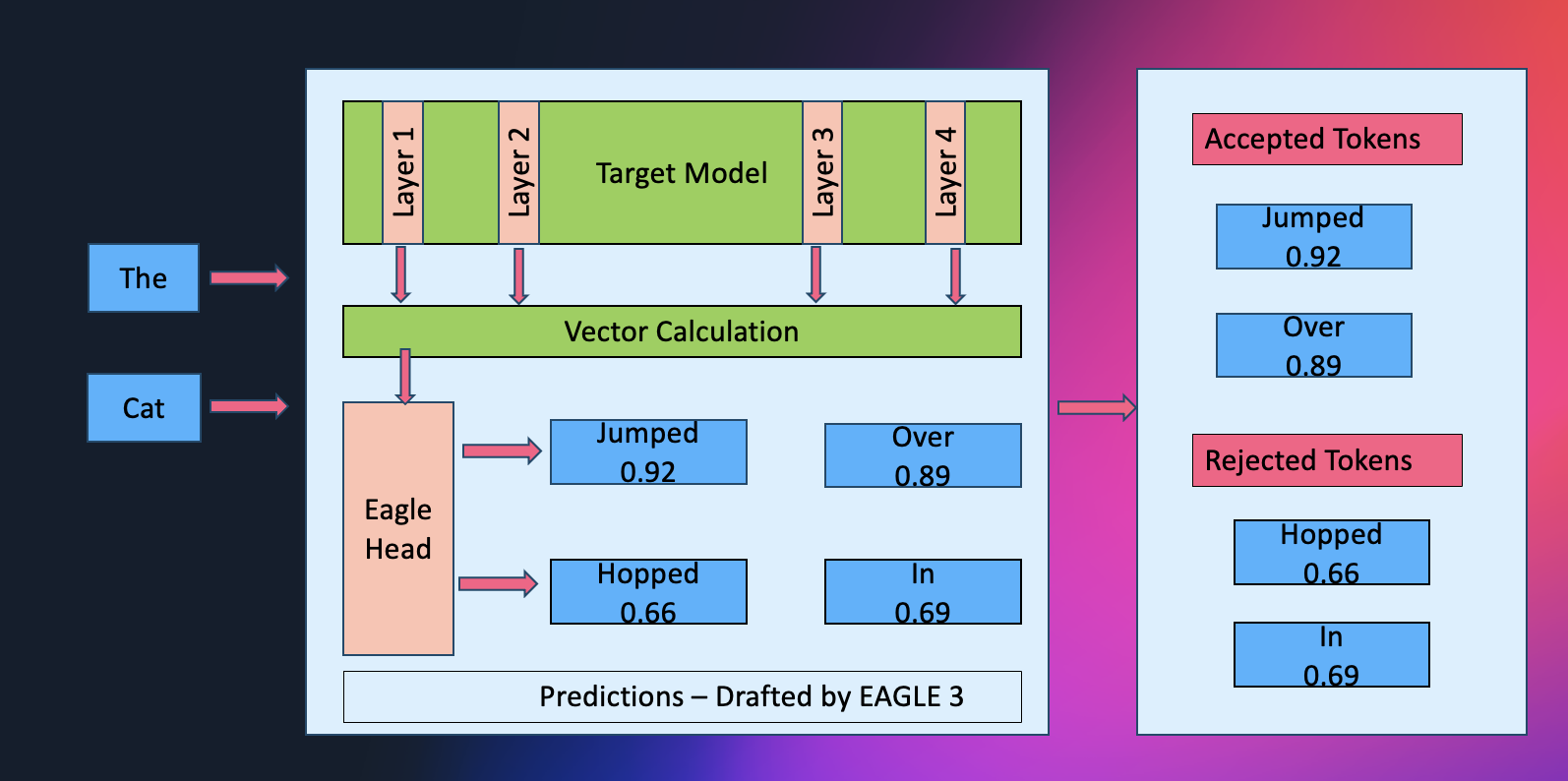
Visão Geral da Solução
O SageMaker AI agora oferece suporte nativo para decodificação especulativa com EAGLE 2 e EAGLE 3, permitindo que cada arquitetura de modelo aplique a técnica que melhor se adequa ao seu design interno.
Para seu modelo de base LLM, você pode utilizar modelos do SageMaker JumpStart ou trazer seus próprios artefatos de modelo de outro lugar, como o HuggingFace. A decodificação especulativa é uma técnica amplamente empregada para acelerar inferência em LLMs sem comprometer a qualidade. O método envolve usar um modelo de rascunho menor para gerar tokens preliminares, que são então verificados pelo LLM alvo. A extensão da aceleração obtida por meio da decodificação especulativa depende fortemente da seleção do modelo de rascunho.
A natureza sequencial dos LLMs modernos os torna caros e lentos, e a decodificação especulativa provou ser uma solução eficaz para este problema. Métodos como EAGLE melhoram isso reutilizando recursos do modelo alvo, levando a melhores resultados.
Evolução: Do EAGLE 2 ao EAGLE 3
Uma tendência atual na comunidade de LLM é aumentar dados de treinamento para potencializar a inteligência do modelo sem adicionar custos de inferência. Infelizmente, essa abordagem tem benefícios limitados para EAGLE. Essa limitação ocorre devido às restrições do EAGLE na previsão de recursos.
Para resolver isso, o EAGLE 3 foi introduzido, que prevê tokens diretamente em vez de recursos e combina recursos de múltiplas camadas usando uma técnica chamada teste em tempo de treinamento. Essas mudanças melhoram significativamente o desempenho e permitem que o modelo se beneficie plenamente do aumento de dados de treinamento.
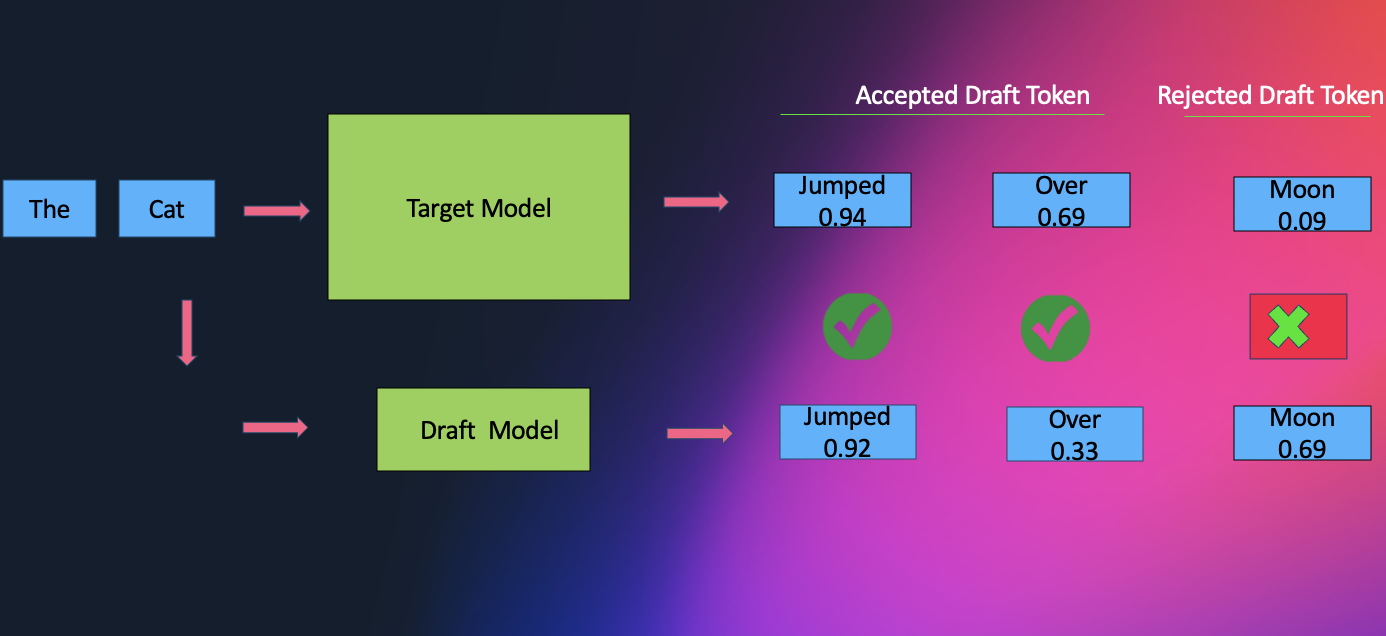
Flexibilidade de Workflows
Para dar aos clientes máxima flexibilidade, o SageMaker suporta todos os principais fluxos de trabalho para construir ou refinar um modelo EAGLE:
- Treinar um modelo EAGLE completamente do zero usando o conjunto de dados aberto curado pelo SageMaker
- Treinar do zero com seus próprios dados para alinhar o comportamento especulativo com seus padrões de tráfego
- Começar a partir de um modelo EAGLE base existente, retreinando-o com o conjunto de dados aberto padrão para uma baseline rápida e de alta qualidade
- Ou ajustar esse modelo base com seu próprio conjunto de dados para desempenho altamente adaptativo e específico à sua carga de trabalho
Além disso, o SageMaker JumpStart fornece modelos EAGLE completamente pré-treinados, permitindo que você comece a otimização imediatamente sem preparar nenhum artefato.
A solução abrange seis arquiteturas suportadas e inclui uma base EAGLE pré-treinada e pré-armazenada em cache para acelerar experimentação. O SageMaker AI também suporta formatos de dados de treinamento amplamente utilizados, especificamente ShareGPT e chat e completude OpenAI, permitindo que corpora existentes sejam usados diretamente. Os clientes também podem fornecer dados capturados usando seus próprios endpoints do SageMaker AI, desde que os dados estejam nos formatos especificados acima.
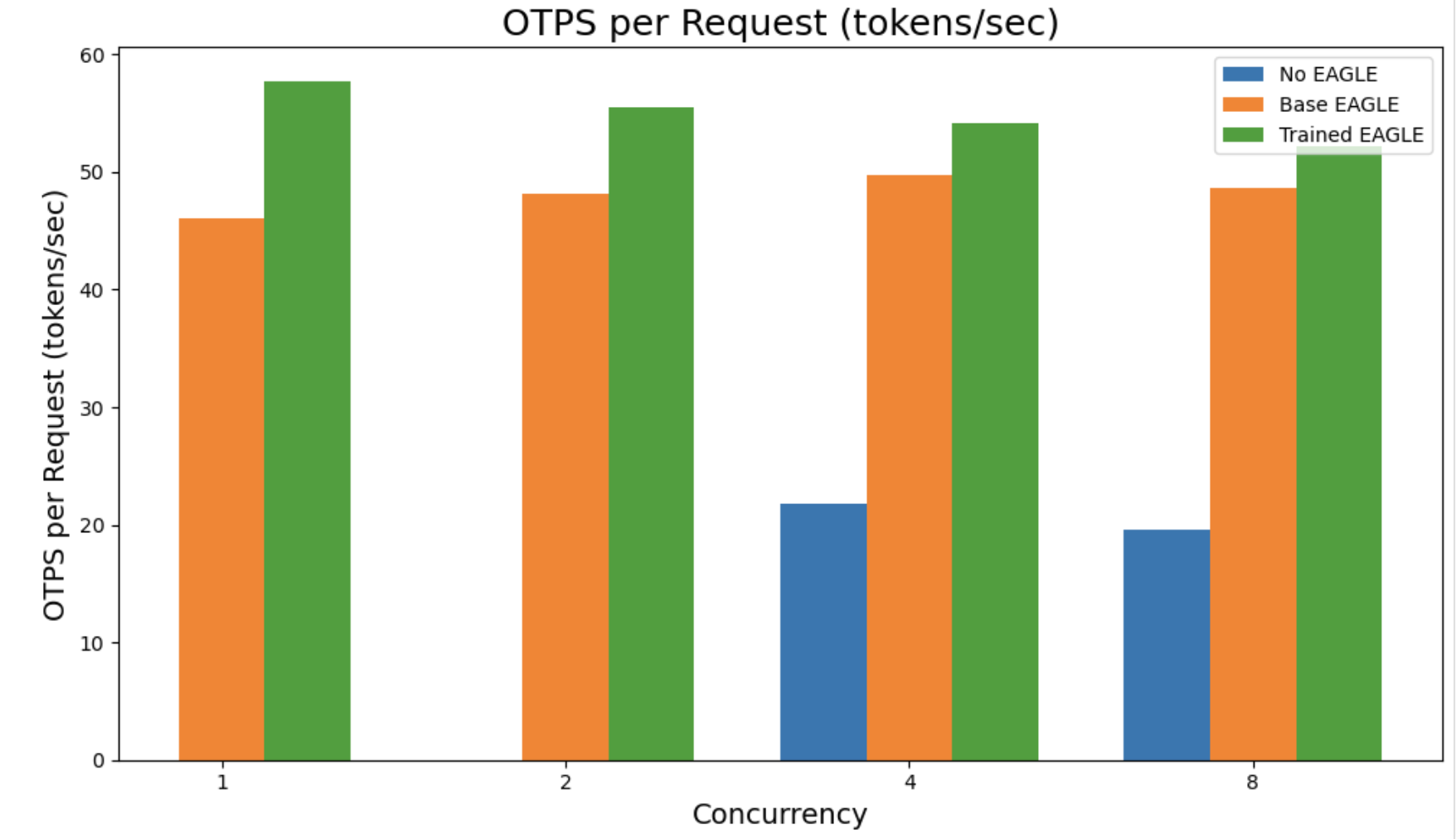
Seja confiando no conjunto de dados aberto do SageMaker ou trazendo seus próprios dados, os trabalhos de otimização normalmente entregam aproximadamente 2.5x de throughput sobre a decodificação padrão, ao mesmo tempo que se adaptam naturalmente às nuances de seu caso de uso específico. Todos os trabalhos de otimização produzem automaticamente resultados de benchmark, dando-lhe visibilidade clara nas melhorias de latência e throughput.
Arquiteturas Suportadas
O SageMaker AI atualmente suporta LlamaForCausalLM, Qwen3ForCausalLM, Qwen3MoeForCausalLM, Qwen2ForCausalLM e GptOssForCausalLM com EAGLE 3, e Qwen3NextForCausalLM com EAGLE 2. Você pode utilizar um pipeline de otimização único em um conjunto de arquiteturas diferentes enquanto ainda obtém os benefícios do comportamento específico de cada modelo.
Como o EAGLE Funciona Internamente
A decodificação especulativa pode ser pensada como um cientista chefe experiente guiando o fluxo de descoberta. Em configurações tradicionais, um modelo "assistente" menor funciona antecipadamente, esboçando rapidamente várias continuações de tokens possíveis, enquanto o modelo maior examina e corrige essas sugestões. Essa combinação reduz o número de passos lentos e sequenciais verificando múltiplos rascunhos de uma vez.
O EAGLE simplifica ainda mais esse processo. Em vez de depender de um assistente externo, o modelo efetivamente se torna seu próprio parceiro de laboratório: inspeciona suas representações de camadas ocultas internas para antecipar vários tokens futuros em paralelo. Como essas previsões surgem da estrutura aprendida do próprio modelo, tendem a ser mais precisas desde o início, levando a etapas especulativas mais profundas, menos rejeições e throughput mais suave.
Ao remover a sobrecarga de coordenação de um modelo secundário e permitir verificação altamente paralela, essa abordagem alivia gargalos de largura de banda de memória e entrega acelerações notáveis, frequentemente em torno de 2.5x, mantendo a mesma qualidade de saída que o modelo de base produziria.
Executando Trabalhos de Otimização
Você pode interagir com o kit de ferramentas de otimização usando o AWS Python Boto3 SDK, Studio UI ou AWS CLI. As chamadas de API principais para criação de endpoint permanecem as mesmas: create_model, create_endpoint_config e create_endpoint.
O fluxo de trabalho começa com registro de modelo usando a chamada da API create_model. Com essa chamada você pode especificar seu contêiner de serviço e stack. Você não precisa criar um objeto de modelo SageMaker e pode especificar os dados do modelo também na chamada da API do Trabalho de Otimização.
Para otimização de cabeçalhos EAGLE, você especifica os dados do modelo apontando para o parâmetro Fonte de Dados do Modelo. No momento, especificação do ID do Modelo do HuggingFace Hub não é suportada. Extraia seus artefatos e carregue-os em um bucket S3 e especifique-o no parâmetro Fonte de Dados do Modelo.
Por padrão, verificações são realizadas para confirmar que os arquivos apropriados foram carregados, garantindo que você tenha os dados padrão esperados para LLMs:
model/
config.json
tokenizer.json
tokenizer_config.json
special_tokens_map.json
generation_config.json
vocab.json
model.safetensors
model.safetensors.index.jsonUsando seus próprios dados de modelo com dataset EAGLE curado
Você pode iniciar um trabalho de otimização com a chamada da API create-optimization-job. Aqui está um exemplo com um modelo Qwen3 32B. Note que você pode trazer seus próprios dados ou também usar os conjuntos de dados fornecidos pelo SageMaker.
Primeiro, crie um objeto de Modelo SageMaker que especifique o bucket S3 com seus artefatos de modelo:
aws sagemaker --region us-west-2 create-model \
--model-name \
--primary-container '{
"Image": "763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:{CONTAINER_VERSION}",
"ModelDataSource": {
"S3DataSource": {
"S3Uri": "Enter model path",
"S3DataType": "S3Prefix",
"CompressionType": "None"
}
}
}' \
--execution-role-arn "Enter Execution Role ARN" Sua chamada de otimização então extrai esses artefatos de modelo quando você especifica o Modelo SageMaker e um parâmetro TrainingDataSource da seguinte forma:
aws sagemaker --region us-west-2 create-optimization-job \
--optimization-job-name \
--account-id \
--deployment-instance-type ml.p5.48xlarge \
--max-instance-count 10 \
--model-source '{
"SageMakerModel": {
"ModelName": "Created Model name"
}
}' \
--optimization-configs '{
"ModelSpeculativeDecodingConfig": {
"Technique": "EAGLE",
"TrainingDataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "Enter custom train data location"
}
}
}' \
--output-config '{
"S3OutputLocation": "Enter optimization output location"
}' \
--stopping-condition '{"MaxRuntimeInSeconds": 432000}' \
--role-arn "Enter Execution Role ARN" Trazendo seu próprio EAGLE treinado
Para seu próprio EAGLE treinado, você pode especificar outro parâmetro na chamada da API create_model onde aponta para seus artefatos EAGLE. Opcionalmente, você também pode especificar um ID de Modelo SageMaker JumpStart para extrair os artefatos de modelo empacotados:
aws sagemaker --region us-west-2 create-model \
--model-name \
--primary-container '{
"Image": "763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:{CONTAINER_VERSION}",
"ModelDataSource": {
"S3DataSource": {
"S3Uri": "",
"S3DataType": "S3Prefix",
"CompressionType": "None"
}
},
"AdditionalModelDataSources": [
{
"ChannelName": "eagle_model",
"S3DataSource": {
"S3Uri": "",
"S3DataType": "S3Prefix",
"CompressionType": "None"
}
}
]
}' \
--execution-role-arn "Enter Execution Role ARN" De forma similar, a API de otimização então herda esse objeto de modelo com os dados de modelo necessários:
aws sagemaker --region us-west-2 create-optimization-job \
--account-id \
--optimization-job-name \
--deployment-instance-type ml.p5.48xlarge \
--max-instance-count 10 \
--model-source '{
"SageMakerModel": {
"ModelName": "Created Model Name"
}
}' \
--optimization-configs '{
"ModelSpeculativeDecodingConfig": {
"Technique": "EAGLE",
"TrainingDataSource": {
"S3Uri": "Enter training data path",
"S3DataType": "S3Prefix"
}
}
}' \
--output-config '{
"SageMakerModel": {
"ModelName": "Model Name"
},
"S3OutputLocation": "Enter output data location"
}' \
--stopping-condition '{"MaxRuntimeInSeconds": 432000}' \
--role-arn "Enter Execution Role ARN" Usando dados de modelo próprio com conjuntos de dados incorporados
Opcionalmente, você pode utilizar os conjuntos de dados fornecidos pelo SageMaker:
- gsm8k_training.jsonl
- magicoder.jsonl
- opencodeinstruct.jsonl
- swebench_oracle_train.jsonl
- ultrachat_0_8k_515292.jsonl
Após conclusão, o SageMaker AI armazena métricas de avaliação no S3 e registra a linhagem de otimização no Studio. Você pode fazer deploy do modelo otimizado para um endpoint de inferência com a chamada da API create_endpoint ou na interface.
Resultados de Benchmark
Para benchmarks, foram comparados três estados: sem EAGLE como baseline, EAGLE base usando conjuntos de dados incorporados, e EAGLE treinado usando datasets incorporados e retreinamento com dados customizados próprios.
Os números exibidos abaixo são para Qwen3-32B em métricas como Tempo para Primeiro Token (TTFT) e throughput geral:
Considerações sobre Preços
Os trabalhos de otimização são executados em instâncias de treinamento do SageMaker AI, e você será cobrado dependendo do tipo de instância e duração do trabalho. O deploy do modelo otimizado resultante usa a precificação padrão de Inferência do SageMaker AI.
Conclusão
A decodificação especulativa adaptativa baseada em EAGLE oferece um caminho mais rápido e eficaz para melhorar o desempenho de inferência de IA generativa no Amazon SageMaker AI. Ao funcionar dentro do modelo em vez de depender de uma rede de rascunho separada, o EAGLE acelera a decodificação, aumenta o throughput e mantém a qualidade da geração. Quando você otimiza usando seu próprio conjunto de dados, as melhorias refletem o comportamento único de suas aplicações, resultando em melhor desempenho de ponta a ponta.
Com suporte a conjuntos de dados incorporados, automação de benchmarks e deployment simplificado, o kit de ferramentas de otimização de inferência ajuda você a entregar aplicações de IA generativa de baixa latência em escala.
Fonte
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference (https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-ai-introduces-eagle-based-adaptive-speculative-decoding-to-accelerate-generative-ai-inference/)