Infraestrutura de IA com múltiplas demandas simultâneas
Ambientes modernos de inteligência artificial executam várias tarefas em paralelo no mesmo cluster: pré-treinamento de modelos foundation (FM), ajuste fino (fine-tuning), inferência em produção e avaliação. Nesse contexto compartilhado, a demanda por aceleradores de IA oscila continuamente — cargas de trabalho de inferência crescem conforme padrões de tráfego, e experimentos terminam liberando recursos.
Apesar dessa disponibilidade dinâmica de aceleradores, os trabalhos de treinamento tradicionais permanecem presos à sua alocação computacional inicial, incapazes de aproveitar capacidade ociosa sem intervenção manual. O SageMaker HyperPod agora suporta treinamento elástico, permitindo que cargas de trabalho de aprendizado de máquina dimensionem automaticamente conforme a disponibilidade de recursos. Essa abordagem maximiza utilização de GPU, reduz custos e acelera desenvolvimento de modelos através da adaptação dinâmica de recursos, mantendo qualidade de treinamento e minimizando intervenção manual.
O problema da alocação estática de recursos
Considere um cluster de 256 GPUs executando simultaneamente treinamento e inferência. Durante as horas de menor tráfego à noite, a inferência pode liberar 96 GPUs. Essas 96 GPUs ficam ociosas e disponíveis para acelerar o treinamento. Porém, trabalhos de treinamento tradicionais rodam em escala fixa — um trabalho que começa com 32 GPUs fica preso a essa configuração inicial, enquanto 96 GPUs adicionais permanecem ociosas. Isso representa 2.304 horas GPU desperdiçadas por dia, traduzindo-se em milhares de dólares gastos diariamente em infraestrutura subutilizada.
O problema se intensifica conforme o cluster cresce. Dimensionar treinamento distribuído dinamicamente é tecnicamente complexo. Mesmo com infraestrutura que suporta elasticidade, é necessário pausar trabalhos, reconfigurar recursos, ajustar paralelização e redistribuir checkpoints. Essa complexidade piora pela necessidade de manter progresso de treinamento e acurácia do modelo através dessas transições. Apesar de suporte subjacente do SageMaker HyperPod com Amazon EKS e frameworks como PyTorch e NeMo, intervenção manual ainda consome horas de tempo de engenharia.
A necessidade de ajustar repetidamente execuções de treinamento conforme disponibilidade de aceleradores distrai equipes de seu trabalho real: desenvolvimento de modelos. Compartilhamento de recursos e preempção de cargas de trabalho adicionam outra camada de complexidade. Sistemas atuais carecem de capacidade para lidar graciosamente com requisições parciais de recursos de cargas de trabalho prioritárias. Imagine um cenário onde um trabalho crítico de ajuste fino necessita 8 GPUs em um cluster onde uma carga de pré-treinamento ocupa todas as 32 GPUs. Sistemas atuais forçam escolha binária: ou parar o trabalho inteiro de pré-treinamento, ou negar recursos à carga prioritária, ainda que 24 GPUs fossem suficientes para pré-treinamento em escala reduzida. Essa limitação leva organizações a superdimensionar infraestrutura evitando contenção de recursos, resultando em filas maiores de trabalhos pendentes, custos elevados e eficiência de cluster reduzida.
Solução: treinamento elástico automático
A AWS oferece através do SageMaker HyperPod uma solução: treinamento elástico. Cargas de trabalho de treinamento agora dimensionam automaticamente para utilizar aceleradores disponíveis e se contraem graciosamente quando recursos são necessários em outro lugar, tudo mantendo qualidade de treinamento. O SageMaker HyperPod gerencia a orquestração complexa de gerenciamento de checkpoint, reatribuição de classificações e coordenação de processos, minimizando intervenção manual e ajudando equipes focar em desenvolvimento de modelos.
O operador de treinamento do SageMaker HyperPod integra-se com o plano de controle do Kubernetes (K8s) e agendador de recursos para tomar decisões de dimensionamento. Monitora eventos de ciclo de vida de pod, disponibilidade de nó e sinais de prioridade do agendador, detectando oportunidades de dimensionamento quase instantaneamente, tanto de recursos recém-disponíveis quanto de novas requisições de cargas prioritárias. Antes de iniciar qualquer transição, o operador avalia ações de dimensionamento potenciais contra políticas configuradas (limites mínimos e máximos de nó, limites de frequência de dimensionamento).
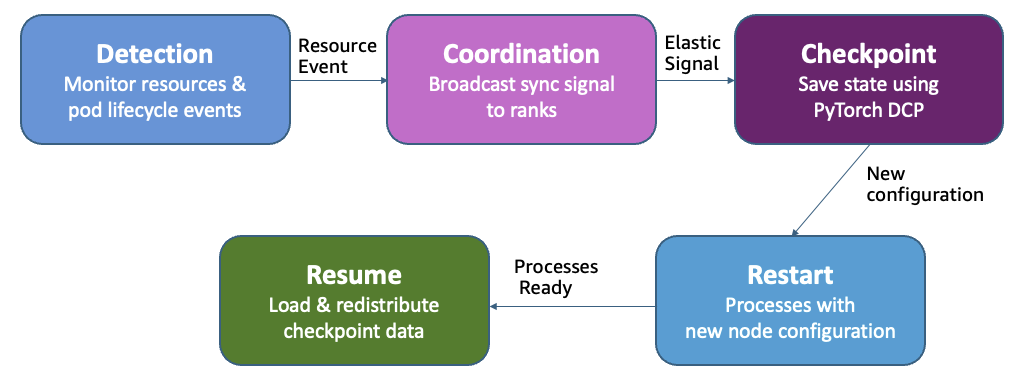
Como funciona o dimensionamento elástico
Treinamento elástico adiciona ou remove réplicas paralelas de dados mantendo tamanho global de lote constante. Quando recursos ficam disponíveis, novas réplicas se integram e aceleram throughput sem afetar convergência. Quando carga prioritária necessita recursos, o sistema remove réplicas em vez de matar o trabalho inteiro. Treinamento continua em capacidade reduzida.
Quando evento de dimensionamento ocorre, o operador transmite sinal de sincronização para todas as classificações (ranks). Cada processo conclui passo atual e salva estado usando Checkpoint Distribuído do PyTorch (DCP — Distributed Checkpoint). Conforme novas réplicas se integram ou existentes saem, o operador recalcula atribuições de classificação e inicia reinicializações de processos através do trabalho de treinamento. DCP então carrega e redistribui dados de checkpoint para corresponder à nova contagem de réplica, garantindo que cada worker tenha estado correto de modelo e otimizador. Treinamento retoma com réplicas ajustadas, e tamanho global de lote constante garante convergência não afetada.
Para clusters usando Kueue (incluindo SageMaker HyperPod task governance), treinamento elástico implementa gerenciamento inteligente de carga de trabalho através de múltiplas requisições de admissão. O operador primeiro requisita recursos mínimos necessários com prioridade alta, depois incrementalmente requisita capacidade adicional com prioridade mais baixa. Essa abordagem habilita preempção parcial: quando cargas prioritárias necessitam recursos, apenas réplicas de prioridade mais baixa são revogadas, permitindo treinamento continuar na linha de base garantida em vez de terminar completamente.
Começando com treinamento elástico
Pré-requisitos
Antes de integrar treinamento elástico em sua carga de trabalho de treinamento, certifique-se que seu ambiente atende aos seguintes requisitos:
- Cluster SageMaker HyperPod orquestrado por Amazon EKS com Kubernetes v1.32 ou superior
- HyperPod training operator v1.2 ou superior instalado no cluster
- SageMaker HyperPod task governance v1.3.1 ou superior para enfileiramento, priorização e agendamento de trabalhos
Configurar isolamento de namespace e controles de recurso
Se usar escalonamento automático de cluster (como Karpenter), configure ResourceQuotas no nível de namespace. Sem elas, requisições de recurso do treinamento elástico podem disparar provisionamento ilimitado de nó. ResourceQuotas limitam máximo de recursos que trabalhos podem requisitar mantendo ainda comportamento elástico dentro de limites definidos.
Exemplo de ResourceQuota para namespace limitado a 8 instâncias ml.p5.48xlarge (cada instância possui 8 GPUs NVIDIA H100, 192 vCPUs e 640 GiB memória, totalizando 64 GPUs, 1.536 vCPUs e 5.120 GiB memória):
apiVersion: v1
kind: ResourceQuota
metadata:
name: training-quota
namespace: team-ml
spec:
hard:
nvidia.com/gpu: "64"
vpc.amazonaws.com/efa: "256"
requests.cpu: "1536"
requests.memory: "5120Gi"
limits.cpu: "1536"
limits.memory: "5120Gi"Recomenda-se organizar cargas de trabalho em namespaces separados por time ou projeto, com AWS Identity and Access Management (IAM) mapeamentos de controle de acesso baseado em papéis (RBAC) suportando controle de acesso apropriado e isolamento de recursos.
Construir container de treinamento HyperPod
O operador de treinamento HyperPod usa launcher customizado do PyTorch do pacote Python HyperPod Elastic Agent para detectar eventos de dimensionamento, coordenar operações de checkpoint e gerenciar processo de rendezvous quando world size muda. Instale o agente elástico, depois substitua torchrun por hyperpodrun em seu comando de inicialização. Veja HyperPod elastic agent para mais detalhes.
Exemplo de configuração de container de treinamento:
FROM
RUN pip install hyperpod-elastic-agent
ENTRYPOINT ["entrypoint.sh"]
# entrypoint.sh
hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \
--rdzv-backend hyperpod Habilitar dimensionamento elástico no código de treinamento
Complete os seguintes passos para habilitar dimensionamento elástico em seu código de treinamento:
1. Adicione importação do agente elástico HyperPod ao script de treinamento:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected2. Modifique seu loop de treinamento para verificar eventos elásticos após cada lote:
def train_epoch(model, dataloader, optimizer, args):
for batch_idx, batch_data in enumerate(dataloader):
# Forward and backward pass
loss = model(batch_data).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Check if we should checkpoint (periodic or scaling event)
should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0
elastic_event = elastic_event_detected()
# Save checkpoint if scaling-up or scaling down job
if should_checkpoint or elastic_event:
save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step)
if elastic_event:
print("Elastic scaling event detected. Checkpoint saved.")
return3. Implemente funções de salvar e carregar checkpoint usando PyTorch DCP:
import torch.distributed.checkpoint as dcp
from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict
def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path):
"""Save checkpoint using DCP for elastic training."""
state_dict = {
"model": model,
"optimizer": optimizer,
"lr_scheduler": lr_scheduler,
**user_content
}
dcp.save(
state_dict=state_dict,
storage_writer=dcp.FileSystemWriter(checkpoint_path)
)
def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path):
"""Load checkpoint using DCP with automatic resharding."""
state_dict = {
"model": model,
"optimizer": optimizer,
"lr_scheduler": lr_scheduler
}
dcp.load(
state_dict=state_dict,
storage_reader=dcp.FileSystemReader(checkpoint_path)
)
return model, optimizer, lr_schedulerPara cenários de treinamento de época única onde cada amostra deve ser vista exatamente uma vez, é necessário persistir estado do dataloader através de eventos de dimensionamento. Sem isso, quando seu trabalho retoma com world size diferente, amostras processadas previamente podem ser repetidas ou puladas, afetando qualidade de treinamento.
Submeter trabalho de treinamento elástico
Com container de treinamento construído e código instrumentado, você está pronto submeter trabalho de treinamento elástico. Especificação de trabalho define como sua carga de trabalho dimensiona respondendo à disponibilidade de recursos de cluster através da configuração elasticPolicy.
Crie especificação HyperPodPyTorchJob definindo seu comportamento de dimensionamento elástico:
apiVersion: sagemaker.amazonaws.com/v1
kind: HyperPodPyTorchJob
metadata:
name: elastic-training-job
spec:
elasticPolicy:
minReplicas: 2
maxReplicas: 8
replicaIncrementStep: 2
gracefulShutdownTimeoutInSeconds: 600
scalingTimeoutInSeconds: 60
faultyScaleDownTimeoutInSeconds: 30
replicaSpecs:
- name: worker
replicas: 2
maxReplicas: 8
template:
spec:
containers:
- name: pytorch
image:
command: ["hyperpodrun"]
args:
- "--nnodes=2"
- "--nproc-per-node=8"
- "--rdzv-backend=hyperpod"
- "train.py"
resources:
requests:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32
limits:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32 Configuração elasticPolicy controla como seu trabalho de treinamento responde a mudanças de recurso:
- minReplicas e maxReplicas: Definem limites de dimensionamento. Seu trabalho manterá sempre pelo menos minReplicas e nunca excederá maxReplicas, mantendo uso de recurso previsível.
- replicaIncrementStep vs. replicaDiscreteValues: Escolha uma abordagem para granularidade de dimensionamento. Use replicaIncrementStep para dimensionamento uniforme. Use replicaDiscreteValues: [2, 4, 8] para especificar configurações exatas permitidas.
- gracefulShutdownTimeoutInSeconds: Oferece tempo para processo de treinamento completar checkpoint antes de forçado encerramento. Configure baseado em tamanho de checkpoint e desempenho de armazenamento.
- scalingTimeoutInSeconds: Introduz atraso de estabilização antes de scale-up prevenindo flutuações quando recursos oscilam rapidamente.
- faultyScaleDownTimeoutInSeconds: Quando pods falham ou travam, operador aguarda essa duração para recuperação antes de dimensionar. Previne scale-downs desnecessários por falhas transitórias.
Treinamento elástico incorpora mecanismos anti-thrashing para manter estabilidade em ambientes com disponibilidade de recurso flutuando rapidamente. Essas proteções incluem períodos mínimos de estabilidade reforçados entre eventos de dimensionamento e estratégia exponencial de backoff para transições frequentes.
Submeta o trabalho usando kubectl ou SageMaker HyperPod CLI:
kubectl apply -f elastic-job.yamlUsar receitas SageMaker HyperPod
A AWS criou SageMaker HyperPod recipes para treinamento elástico de modelos foundation publicamente disponíveis, incluindo Llama e GPT-OSS. Essas receitas fornecem configurações pré-validadas tratando estratégia de paralelização, ajustes de hiperparâmetro e gerenciamento de checkpoint automaticamente, requerendo apenas mudanças de configuração YAML sem modificações de código.
Times simplesmente especificam limites mínimos e máximos de nó em sua especificação de trabalho, e sistema gerencia toda coordenação de dimensionamento conforme recursos de cluster flutuam:
python launcher.py \
recipes=llama/llama3_1_8b_sft \
recipes.elastic_policy.is_elastic=true \
recipes.elastic_policy.min_nodes=2 \
recipes.elastic_policy.max_nodes=8Receitas também suportam configurações específicas por escala através do campo scale_config, permitindo definir diferentes hiperparâmetros (tamanho de lote, taxa de aprendizado) para cada world size. Veja SageMaker HyperPod Recipes repository para exemplos detalhados.
Resultados de desempenho
Para demonstrar impacto de treinamento elástico, ajuste fino de modelo Llama-3 70B foi realizado no dataset TAT-QA usando cluster SageMaker HyperPod com até 8 instâncias ml.p5.48xlarge. Esse benchmark ilustra como treinamento elástico executa na prática quando dimensionando dinamicamente respondendo à disponibilidade de recursos, simulando ambiente realista onde treinamento e cargas de inferência compartilham capacidade de cluster.
Avaliação cobriu duas dimensões chave: throughput de treinamento e convergência de modelo durante transições de dimensionamento. Melhoria consistente em throughput em diferentes configurações de dimensionamento de 1 a 8 nós foi observada. Desempenho de treinamento melhorou de 2.000 tokens/segundo em 1 nó para até 14.000 tokens/segundo em 8 nós.
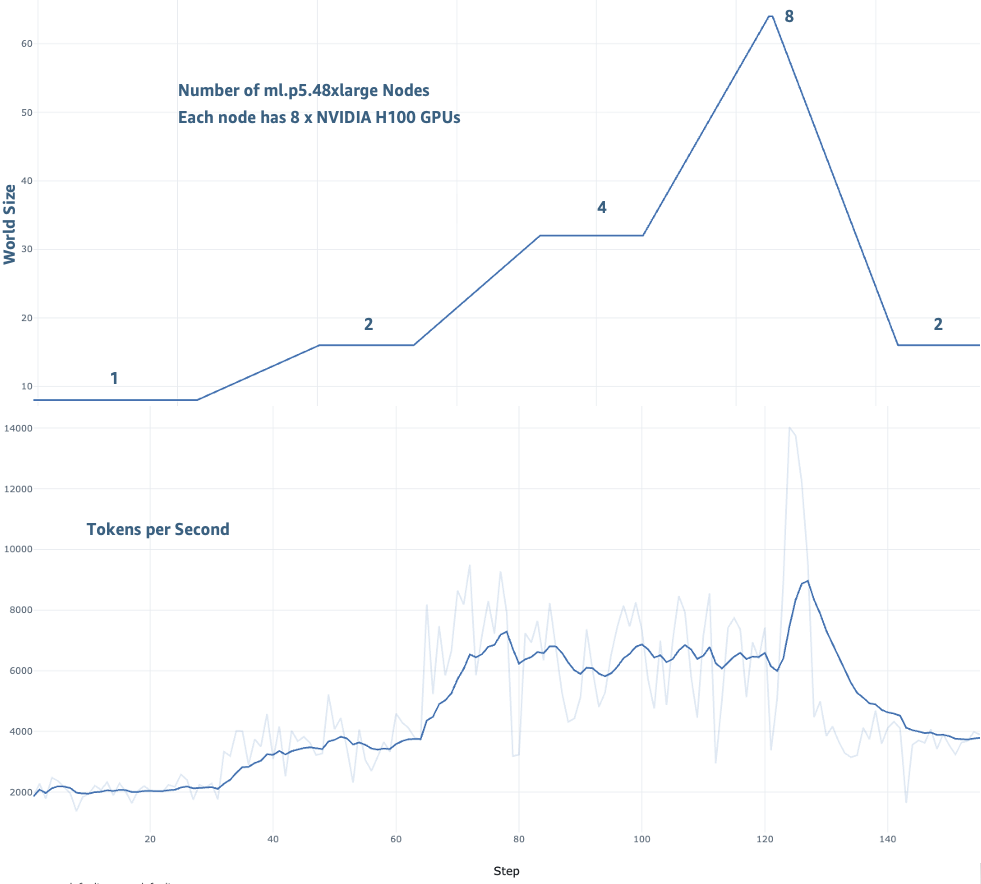
Durante toda execução de treinamento, loss continuou diminuindo conforme treinamento de modelo continuou convergindo:

Integração com capacidades do SageMaker HyperPod
Além suas capacidades essenciais de dimensionamento, treinamento elástico aproveita integração com capacidades de infraestrutura do SageMaker HyperPod. Task governance policies automaticamente disparam eventos de dimensionamento quando prioridades de carga de trabalho mudam, habilitando treinamento ceder recursos a cargas prioritárias de inferência ou avaliação. Suporte para SageMaker Training Plans permite treinamento dimensionar oportunisticamente usando tipos de capacidade otimizados por custos mantendo resiliência através de scale-down automático quando instâncias spot são reclamadas. A observability add-on do SageMaker HyperPod complementa essas capacidades fornecendo insights detalhados em eventos de dimensionamento, desempenho de checkpoint e progressão de treinamento, ajudando times monitorar e otimizar suas deployments de treinamento elástico.
Conclusão
Treinamento elástico no SageMaker HyperPod endereça problema de recursos desperdiçados em clusters de IA. Trabalhos de treinamento agora dimensionam automaticamente conforme recursos ficam disponíveis sem requerer ajustes manuais de infraestrutura. Arquitetura técnica de treinamento elástico mantém qualidade de treinamento através de transições de dimensionamento. Preservando tamanho global de lote e taxa de aprendizado através de diferentes configurações paralelas de dados, sistema mantém propriedades de convergência consistentes independentemente de escala atual.
Três benefícios primários são esperados: primeiro, perspectiva operacional, redução de ciclos de reconfiguração manual fundamentalmente muda como times de aprendizado de máquina trabalham. Engenheiros podem focar em inovação e desenvolvimento de modelos em vez de gerenciamento de infraestrutura, melhorando significativamente produtividade de time e reduzindo overhead operacional. Segundo, eficiência de infraestrutura vê melhorias dramáticas conforme cargas de trabalho de treinamento dinamicamente consomem capacidade disponível, levando a reduções substanciais em horas GPU ociosas e correspondentes economias de custo. Terceiro, time-to-market acelera consideravelmente conforme trabalhos de treinamento automaticamente dimensionam utilizando recursos disponíveis, habilitando desenvolvimento e deployment de modelo mais rápido.
Para começar, consulte a documentation guide. Implementações de amostra e receitas estão disponíveis no e GitHub repository.
Fonte
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPod (https://aws.amazon.com/blogs/machine-learning/adaptive-infrastructure-for-foundation-model-training-with-elastic-training-on-sagemaker-hyperpod/)