O Ponto de Inflexão no Treinamento de Modelos de Fundação
O treinamento de modelos de fundação atingiu um ponto crítico. À medida que os modelos crescem para trilhões de parâmetros e os aglomerados de treinamento se expandem para milhares de aceleradores de IA, os métodos tradicionais de recuperação baseados em checkpoints se tornaram um gargalo significativo para eficiência e rentabilidade. Até mesmo interrupções menores podem resultar em custos substanciais e atrasos consideráveis.
A AWS apresentou o treinamento sem checkpoints no SageMaker HyperPod, uma mudança de paradigma que reduz a necessidade de checkpointing tradicional ao habilitar recuperação de estado entre pares. Os resultados validados em escala de produção mostram redução de 80 a 93% no tempo de recuperação (de 15-30 minutos para menos de 2 minutos) e possibilitam até 95% de produtividade útil em aglomerados com milhares de aceleradores.
Entendendo a Produtividade Útil
O treinamento de modelos de fundação é um dos processos mais intensivos em recursos da IA, envolvendo frequentemente milhões de dólares em gasto de computação em milhares de aceleradores de IA executando por dias ou meses. Devido à sincronização distribuída que caracteriza esses sistemas, até a perda de um único processador causa paralização completa da carga de trabalho.
Para mitigar essas falhas localizadas, a indústria tem dependido de recuperação baseada em checkpoints: salvando periodicamente estados de treinamento em armazenamento durável. Quando uma falha ocorre, a carga de trabalho retoma a partir do último checkpoint salvo. Porém, conforme os modelos crescem de bilhões para trilhões de parâmetros e as cargas de trabalho expandem de centenas para milhares de aceleradores, esse modelo tradicional se tornou cada vez mais insustentável.
Esse desafio levou ao conceito de produtividade útil: o trabalho real realizado por um sistema de treinamento de IA comparado à sua capacidade máxima teórica. Em treinamento de modelos de fundação, a produtividade útil é impactada por falhas do sistema e sobrecarga de recuperação. O hiato entre a throughput máxima teórica e a saída realmente produtiva cresce com: aumento na frequência de falhas (que sobe com o tamanho do aglomerado), tempos de recuperação mais longos (que escalam com tamanho do modelo e aglomerado), e custos mais altos de recursos ociosos durante recuperação.
Impacto Financeiro das Falhas em Larga Escala
Uma carga de trabalho de pré-treinamento em um aglomerado HyperPod com 256 instâncias P5, fazendo checkpoint a cada 20 minutos, enfrenta dois desafios quando interrompida: 10 minutos de trabalho perdido mais 10 minutos para recuperação. Com instâncias ml.p5.24xlarge custando 55 dólares por hora, cada interrupção custa aproximadamente 4.700 dólares em tempo de computação. Para um treinamento de um mês, interrupções diárias acumulam 141.000 dólares em custos extras e atrasam a conclusão em 10 horas.
À medida que aglomerados crescem, a probabilidade e frequência de falhas aumentam proporcionalmente. Quando o treinamento abrange milhares de nós, interrupções se tornam cada vez mais frequentes, enquanto a recuperação fica mais lenta porque a sobrecarga de reinicialização cresce linearmente com o tamanho do aglomerado. O impacto cumulativo pode alcançar milhões de dólares anualmente, traduzindo-se diretamente em atraso no tempo de chegada ao mercado, ciclos mais lentos de iteração de modelo e desvantagem competitiva.
Os Gargalos da Recuperação Baseada em Checkpoints
A recuperação baseada em checkpoints em treinamento distribuído é significativamente mais complexa do que geralmente compreendido. Quando uma falha ocorre, o processo de reinicialização envolve muito mais que simplesmente carregar o último checkpoint. Compreender o que acontece durante a recuperação revela por que leva tanto tempo e por que todo o aglomerado fica ocioso.
A Cascata do Tudo-ou-Nada
Uma única falha — um erro de GPU, timeout de rede ou falha de hardware — pode desencadear o desligamento completo do aglomerado de treinamento. Como o treinamento distribuído trata todos os processos como fortemente acoplados, qualquer falha única necessita reinicialização completa. O sistema de orquestração deve encerrar cada processo em todos os nós e reiniciar do zero.
Cada reinicialização navegava por um processo de recuperação complexo com múltiplos estágios sequenciais e bloqueadores:
- Estágio 1: Reinicialização do trabalho de treinamento — O orquestrador detecta a falha, encerra todos os processos e inicia reinicialização do aglomerado.
- Estágio 2: Inicialização de processos e rede — Cada processo deve re-executar o script de treinamento desde o início, incluindo inicialização de rank, carregamento de módulos Python, estabelecimento de topologia e backend de comunicação. A inicialização do grupo de processos sozinha pode levar dezenas de minutos em aglomerados grandes.
- Estágio 3: Recuperação de checkpoint — Cada processo deve identificar o último checkpoint completamente salvo, recuperá-lo do armazenamento persistente e carregar múltiplos dicionários de estado: parâmetros do modelo, estado interno do otimizador, agendador de taxa de aprendizado e metadados do loop de treinamento. Isso pode levar dezenas de minutos ou mais.
- Estágio 4: Inicialização do carregador de dados — Os ranks de carregamento de dados devem inicializar buffers, recuperar checkpoint de dados e fazer pré-carregamento de dados de treinamento. Esse processo pode levar vários minutos.
- Estágio 5: Overhead do primeiro passo — Após checkout e dados serem carregados, há overhead adicional no primeiro passo de treinamento.
- Estágio 6: Overhead de passos perdidos — Todos os passos computados entre o checkpoint e a falha precisam ser recomputados.
Somente após todos esses estágios completarem com sucesso o loop de treinamento pode retomar progresso produtivo. Como o treinamento retoma do último checkpoint salvo, todos os passos entre o checkpoint e a falha são perdidos e precisam ser recalculados.
Como o Treinamento Sem Checkpoints Elimina Esses Gargalos
Os cinco estágios descritos acima representam os gargalos fundamentais na recuperação baseada em checkpoints. Cada estágio é sequencial e bloqueador, e a recuperação pode levar de minutos a várias horas para modelos grandes. Criticamente, todo o aglomerado deve esperar cada estágio completar antes que o treinamento possa retomar.
O treinamento sem checkpoints elimina essa cascata. Preserva coerência de estado do modelo no aglomerado distribuído, eliminando a necessidade de snapshots periódicos. Quando falhas ocorrem, o sistema se recupera rapidamente usando pares saudáveis, evitando operações de I/O de armazenamento e reinicializações de processo completas.
Arquitetura do Treinamento Sem Checkpoints
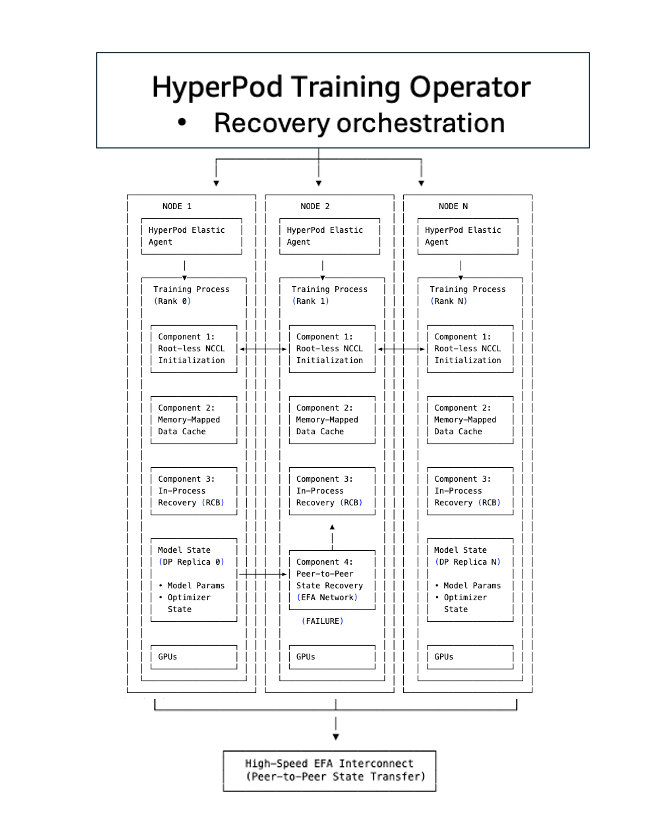
O treinamento sem checkpoints é construído sobre cinco componentes que trabalham juntos para eliminar os gargalos tradicionais de checkpoint-reinicialização:
Componente 1: Inicialização NCCL e Gloo sem TCPStore e sem raiz
Em configuração tradicional de treinamento distribuído, todos os ranks devem inicializar um grupo de processos. Um TCPStore geralmente serve como ponto de encontro onde todos os ranks se registram para descobrir informações de conexão. Quando milhares de ranks tentam contatar um servidor raiz designado simultaneamente, isso se torna um gargalo, causando congestionamento de rede e aumentando latência em dezenas de minutos.
O treinamento sem checkpoints elimina essa dependência centralizada. Em vez de canalizar todos os pedidos de conexão através de um servidor raiz, o sistema usa padrão de endereço simétrico onde cada rank computa independentemente informações de conexão de pares. Ranks se conectam diretamente usando atribuições de porta predeterminadas, evitando o gargalo do TCPStore. A inicialização do grupo de processos cai de dezenas de minutos para segundos, mesmo em aglomerados com milhares de nós.
Componente 2: Carregamento de Dados com Memory-Mapped
Um dos custos ocultos na recuperação tradicional é recarregar dados de treinamento. Quando um processo reinicia, deve recarregar lotes do disco, reconstruir estado do carregador de dados e se posicionar cuidadosamente para evitar duplicação ou pula de dados.
O treinamento sem checkpoints usa carregamento de dados com memory-mapped para manter dados em cache entre aceleradores. Dados de treinamento são mapeados em regiões de memória compartilhada que persistem mesmo quando processos individuais falham. Quando um nó se recupera, não recarrega dados do disco mas se reconecta ao cache memory-mapped existente. O estado do carregador de dados é preservado, garantindo que treinamento continue a partir da posição correta sem duplicação ou pula de amostras.

Componente 3: Recuperação em Processo
A recuperação tradicional baseada em checkpoints trata falhas como eventos no nível do trabalho: um único erro de GPU desencadeia encerramento de todo o trabalho de treinamento distribuído. Cada processo no aglomerado deve ser interrompido e reiniciado, mesmo que apenas um componente tenha falhado.
O treinamento sem checkpoints usa recuperação em processo para isolar falhas no nível do processo. Quando uma GPU ou processo falha, apenas o processo falhado executa recuperação em processo para se reintegrar ao loop de treinamento em segundos. Processos saudáveis continuam executando sem interrupção. O processo falhado permanece ativo, preservando contexto CUDA, cache do compilador e estado da GPU, eliminando minutos de overhead de reinicialização.
Em casos onde o erro é não-recuperável, como falha de hardware, o sistema automaticamente substitui o componente defeituoso com um substituto pré-aquecido, habilitando treinamento continuar sem interrupções.
Componente 4: Replicação de Estado Entre Pares
A recuperação baseada em checkpoints requer carregar estado de modelo e otimizador do armazenamento persistente. Para modelos com bilhões a trilhões de parâmetros, isso significa transferir dezenas a centenas de gigabytes pela rede, desserializar dicionários de estado e reconstruir buffers do otimizador — tudo podendo levar dezenas de minutos.
A inovação mais crítica é replicação contínua de estado entre pares. Em vez de salvar periodicamente estado do modelo em armazenamento centralizado, cada GPU mantém cópias redundantes de seus shards de modelo em GPUs pares. Quando uma falha ocorre, o processo em recuperação não carrega de Amazon S3. Copia estado diretamente de um par saudável sobre a rede de interconexão de alta velocidade Elastic Fabric Adapter (EFA). Essa arquitetura entre pares elimina o gargalo de I/O que domina recuperação de checkpoint tradicional. Transferência de estado acontece em segundos, comparado a minutos para carregar checkpoints de multi-gigabyte do armazenamento.
Componente 5: Operador de Treinamento do SageMaker HyperPod
O operador de treinamento do SageMaker HyperPod orquestra os componentes do treinamento sem checkpoints, servindo como camada de coordenação que liga inicialização, carregamento de dados, recuperação sem checkpoints e mecanismos de fallback de checkpoint. Mantém plano de controle centralizado com visão global de saúde de processos de treinamento em todo o aglomerado.
O operador implementa escalação inteligente de recuperação: primeiro tenta reinicialização em processo para componentes falhados, e se não for viável, escalona para recuperação no nível do processo. Quando falhas ocorrem, o operador transmite sinais de parada coordenados para evitar timeouts em cascata e integra com agente de monitoramento de saúde do SageMaker HyperPod para detectar automaticamente problemas de hardware e desencadear recuperação sem intervenção manual.
Começando com Treinamento Sem Checkpoints
Pré-requisitos
Antes de integrar treinamento sem checkpoints em sua carga de trabalho, verifique se seu ambiente atende aos seguintes requisitos:
Requisitos de Infraestrutura:
- Aglomerado SageMaker HyperPod orquestrado por Amazon Elastic Kubernetes Service (EKS)
- Operador de treinamento HyperPod v1.2 ou posterior instalado no aglomerado
- Tipos de instância recomendados: ml.p5, p5e, p5en.48xlarge, ml.p6.p6-b200.48xlarge, ou ml.p6e-gb200.36xlarge
- Tamanho mínimo de aglomerado: Dois nós para recuperação sem checkpoints entre pares
Requisitos de Software:
- Frameworks suportados: Nemo, PyTorch, PyTorch Lightning
- Formatos de dados de treinamento: JSON, JSONGZ (JSON compactado), ou ARROW
- Repositório Amazon Elastic Container Registry (ECR) para imagens de container. Use o container de treinamento sem checkpoints do HyperPod — necessário para inicialização NCCL sem raiz (Nível 1) e recuperação sem checkpoints entre pares (Nível 4)
658645717510.dkr.ecr..amazonaws.com/sagemaker-hyperpod/pytorch-training:2.3.0-checkpointless Fluxo de Trabalho em Camadas
O treinamento sem checkpoints é projetado para adoção incremental. Você pode começar com capacidades básicas e progressivamente habilitar recursos avançados conforme seu treinamento escala. A integração é organizada em quatro níveis:
Nível 1: Otimização de inicialização NCCL — Elimina o gargalo do processo raiz centralizado durante inicialização. Nós descobrem e conectam a pares independentemente. Habilita inicialização de grupo de processos mais rápida (segundos em vez de minutos) e eliminação de ponto único de falha durante startup.
Nível 2: Carregamento de dados memory-mapped — Mantém dados de treinamento em cache em memória compartilhada entre reinicializações de processo, eliminando overhead de recarga de dados durante recuperação.
Nível 3: Recuperação em processo — Isola falhas a processos individuais em vez de requerer reinicializações completas de trabalho. Processos falhados se recuperam independentemente enquanto processos saudáveis continuam treinamento. Habilita recuperação em menos de um minuto de falhas no nível do processo.
Nível 4: Recuperação sem checkpoints (entre pares) — Integração NeMo — Habilita replicação de estado completa entre pares e recuperação. Processos falhados recuperam estado de modelo e otimizador diretamente de réplicas saudáveis sem carregar de armazenamento.
Recomenda-se começar com Nível 1 e validar em seu ambiente. Adicione Nível 2 quando overhead de carregamento de dados se torna um gargalo. Adote Níveis 3 e 4 para máxima resiliência em maiores aglomerados de treinamento.
Resultados de Desempenho
O treinamento sem checkpoints foi validado em escala de produção em múltiplas configurações de aglomerado. Os modelos Amazon Nova mais recentes foram treinados usando essa tecnologia em dezenas de milhares de aceleradores de IA.
O treinamento sem checkpoints demonstrou melhoras significativas em tempo de recuperação, reduzindo consistentemente downtime em 80 a 93% comparado à recuperação tradicional baseada em checkpoints. Em aglomerados com 2.304 GPUs H100, recuperação tradicional levava 15-30 minutos enquanto recuperação sem checkpoints levava menos de 2 minutos — cerca de 87-93% mais rápido.
Essas melhorias em tempo de recuperação têm relação direta com produtividade útil de ML (porcentagem de tempo que seu aglomerado gasta fazendo progresso real em treinamento em vez de ficar ocioso durante falhas). À medida que aglomerados escalam para milhares de nós, frequência de falha aumenta proporcionalmente. Simultaneamente, tempos de recuperação de checkpoint também aumentam com tamanho do aglomerado. Isso cria um problema composto: mais falhas frequentes combinadas com tempos de recuperação mais longos rapidamente erodem produtividade útil em escala.
O treinamento sem checkpoints otimiza toda a pilha de recuperação, habilitando mais de 95% de produtividade útil mesmo em aglomerados com milhares de aceleradores. Estudos internos mostram consistentemente produtividade útil acima de 95% em implantações em larga escala que excedem 2.300 GPUs. Também foi verificado que acurácia de treinamento do modelo não é impactada pelo treinamento sem checkpoints — checksum e bit-wise matching em loss de treinamento foram confirmados em cada passo de treinamento.
Conclusão
O treinamento de modelos de fundação atingiu um ponto de inflexão. À medida que aglomerados escalam para milhares de aceleradores de IA e execuções de treinamento se estendem por meses, o paradigma tradicional de recuperação baseada em checkpoints se tornou cada vez mais um gargalo.
Uma única falha de GPU que anteriormente causaria minutos de downtime agora desencadeia dezenas de minutos de tempo ocioso do aglomerado em milhares de aceleradores, com custos cumulativos alcançando milhões de dólares anualmente.
O treinamento sem checkpoints repensa esse paradigma completamente ao tratar falhas como eventos locais e recuperáveis em vez de catástrofes do aglomerado. Processos falhados recuperam estado de pares saudáveis em segundos, habilitando o resto do aglomerado continuar fazendo progresso. A mudança é fundamental: de "Como reinicializamos rápido?" para "Como evitamos parar?"
Essa tecnologia habilitou mais de 95% de produtividade útil ao treinar em SageMaker HyperPod. Estudos internos em 2.304 GPUs mostram tempos de recuperação caindo de 15-30 minutos para menos de 90 segundos, traduzindo-se em redução de mais de 80% em tempo ocioso de GPU por falha.
Para começar, explore O que é Amazon SageMaker AI. Implementações amostra e receitas estão disponíveis nos repositórios HyperPod checkpointless training e SageMaker HyperPod recipes do GitHub.
Fonte
Checkpointless training on Amazon SageMaker HyperPod: Production-scale training with faster fault recovery (https://aws.amazon.com/blogs/machine-learning/checkpointless-training-on-amazon-sagemaker-hyperpod-production-scale-training-with-faster-fault-recovery/)